简介
介绍图像分类和kNN算法。
图像分类
图像分类是把一副图像赋予一个标签的,标签范围已知。图像分类问题是计算机视觉的核心;其他计算机视觉问题,例如物体检测、分割等,最终都可以看做是图像识别问题。
下面是一副图像,高和宽分别为400和248,包括3个通道RGB。这意味着图像包含$400 \times 248 \times 3 = 297,600$个像素,分类过程就是把这么多像素转换为一个标签。
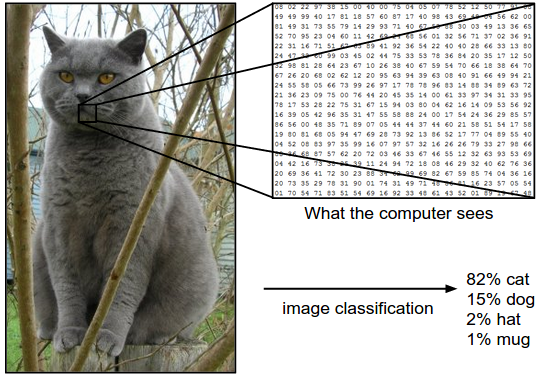
图像分类面临着以下挑战:
1、视角变化:同一个物体在不同角度拍摄的图片不同。
2、比例变化:物体在图片所占比例可能不同。
3、变形:同一个物体,形状会发生有时会改变。
4、遮挡:目标物体有时会被遮挡,仅仅能看到部分物体。
5、光照:光照会影响像素值的大小。
6、背景:目标物体可能混乱在背景噪声中。
7、对象内部差异:一类对象范围很广,例如椅子,有各式各样的的椅子,外表各不相同。
下图是这些挑战的实例。优异的图像分类模型应该能够应对上面这些变化及其组合。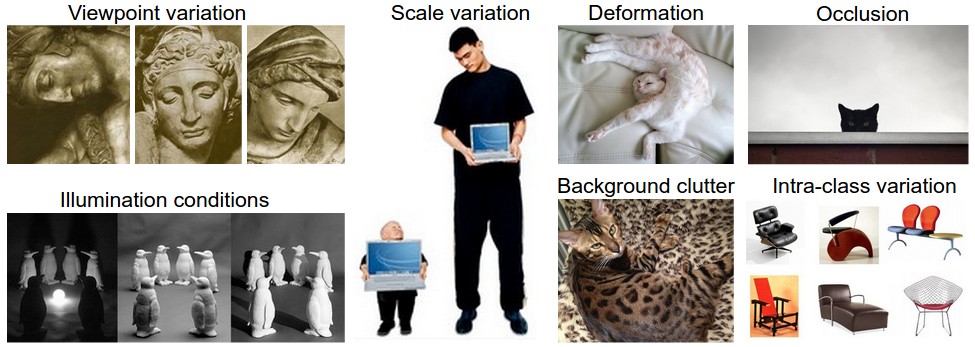
数据驱动
写一个图像分类算法和写一个数字排序算法并不相同,前者不像后者那么直观。像教小孩一样,我们需要大量的有标签的图像来训练一个图像分类算法。这种方法叫做数据驱动。下图就是用来供算法学习的训练集。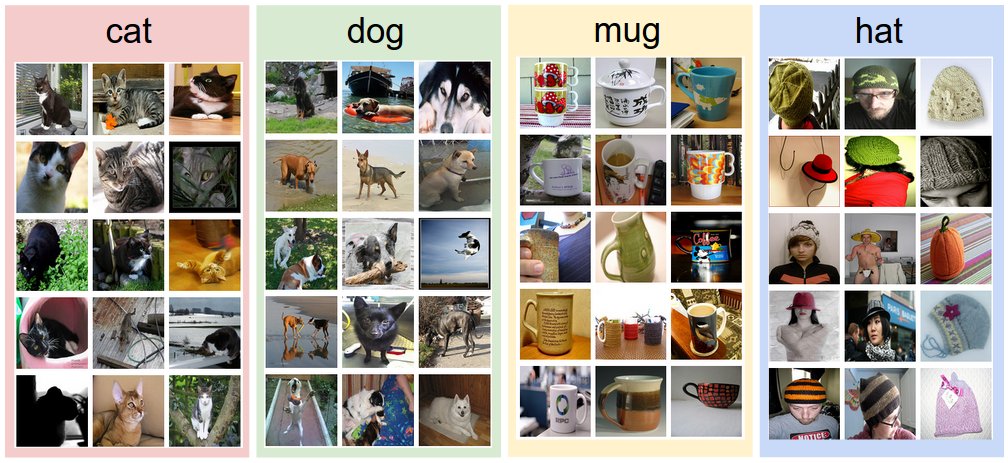
图像学习流程
图像分类的任务就是输入一组像素数据,输出一个标签。其流程吐下:
输入:N个有标签的图片,标签总类别为K。这些训练数据称作训练集。
学习:学习每一类图片的特征。这一步叫做训练或学习模型。
评估:用一个不同于训练集的有标签的集合来评估学好的模型。
最近邻分类器
最近邻分类器和卷积神经网络并不相关,但是它可以让我们学习了解图像分类的一些问题。
图像分类数据集CIFAR-10
CIFAR-10是很流行的小的图片集,它包含60,000张32x32的图片,总共有10个类别,每张图片属于其中一个类别。这60,000张图片分类训练集(50,000)和测试机(10,000)。下图在10类中随机挑选了一些:
如果使用最近邻分类器,具体做法就是把测试机的每张图片和50,000张训练集的图片做对比,找出距离最小的图片就其类别。
怎么对比图片的距离,一张图片有32x32x3个像素,最简单的办法就是对比每个像素值。即,给定两个向量$I_1,I_2$,来计算他们之间的L1距离
$$
d_1(I_1,I_2)=\sum_P|I_1^p-I_2^p|
$$
下图是计算过程的可视化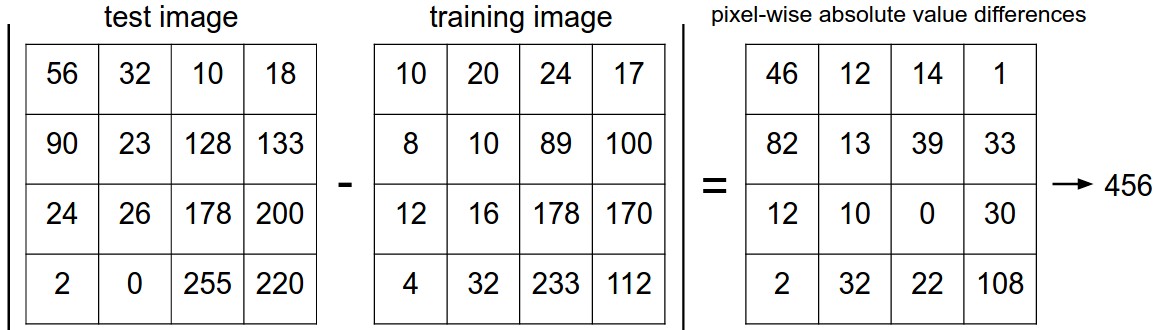
这样的算法,只能达到38.6%左右的识别率,和最优的识别率95%差别很大。
如何选择距离:计算向量之间的距离有很多方式,另外一个常用的就是L2距离,它是计算两个向量之间的高斯距离:
$$
d_1(I_1,I_2)=\sqrt{\sum_P(I_1^p-I_2^p)^2}
$$
使用这个距离,大概可以达到35.4%左右的识别率,比L1距离略低。
L1 vs L2:在对比两个向量的差异时,相比之下,$L2$比$L1$更加不能容忍这些差异。相对于一个大的差异,$L2$能更加容忍几个中等的差异。
这里需要理解,例如3个向量:
$[1,3], [4, 6], [2, 8]$,比较第一个向量和第二三个向量的$L1,L2$距离
$L1$距离为:$4-1+6-3=6$,$2-1+8-3=6$
$L2$距离为:$\sqrt{3^2+3^2}=\sqrt{18}$,$\sqrt{1^2+5^2}=\sqrt{26}$
$L1$距离相同时,$L2$距离却不同,$L2$加上了平方,在$L1$相同时,即差异和相同时,各个差异比较平均情况下,$L2$更小。
##k-Nearest Neighbor分类器
上面例子中,只使用了距离测试图像最近的图片。kNN是使用了k个最近的图片,让k个图片来投票决定测试图片的标签。显然当k=1是就退化为上面的情况了。可以想象,更高的k值可以是分类结果更加平滑。
在实际问题中,图和选择k值,下面就来说明。
验证集用来调优超参数
在使用kNN分类时,k选择多少是最优?在计算距离时,$L1$还是$L2$,或者其他。这些参数叫做超参数hyperparameters,在机器学习的算法中会经常提高超参数这个概念。
在调参时,绝不应该使用测试集。测试集只是用来最后验证算法性能的,如果使用测试集调参,训练的模型在测试集上的表现会过于乐观,可能会造成在测试集的过拟合。
一个正确的做法是把训练集一分为二,一个小的训练集叫做验证集。以CIFAR-10为例,可以ongoing49,000张来训练,1000张当做验证集,在验证集上调参。当训练集比较小时,可以考虑使用交叉验证。
交叉验证,交叉验证是把训练集等分为几份,选择其中一份当做验证集,其余的当做训练集来训练。例如,下图是把数据分为5份,是5折交叉验证。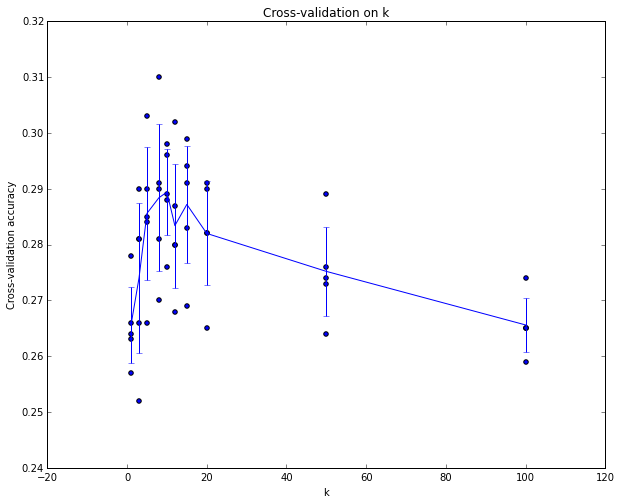
可以看书k=7是最优。5折交叉验证过程如下
实践,在实践中并不经常使用交叉验证,而是单独使用一个验证集,因为交叉验证带来了巨大的计算代价。常常把训练集的50%~90%当做训练集,其余当做验证集。如果验证集图片数量太少,最好还是使用交叉验证,常用的有3折、5折、10折交叉验证。
NN的优缺点
NN十分简单,容易实现和理解,且不需要训练,它需要存储所有训练数据在预测时进行计算。我们常常更加关心预测花费的时间,而不十分关心训练所用时间。实际上,深度卷积网络训练时花费很多时间,但是预测时间很短。
计算复杂度也是一个研究领域,几个Approximate Nearest Neighbor(ANN)算法和一些库可以用来加速。这些算法把精确度和复杂度做了一些trade off,例如预处理或索引建立kdtree,或者使用k-measn。
NN分类器更加适合低维度的数据,在图像分类中很少使用。图像是高维度数据,包含许多像素,高维数据的距离不符合直觉。下面图像的$L2$距离相似,但是图像语义差别很大。

下面这种图更加能说明这一点,相邻紧的图$L2$距离小,可以看出,邻近的图主要是背景或颜色相近,不是语义上的相近。
##总结
本节介绍了图像分类、最近邻分类器(提出了超参数概念)。设置超参数的方法是设置验证集。在训练集样本比较少时,可以使用交叉验证方法。介绍了$L1,L2$距离概念。
##kNN实践总结:
1、预处理数据:对数据进行进行归一化处理,使数据均值为0,方差为1。
2、如果数据维数很高,使用PCA等降维。
3、分割训练集,要有验证集。如果训练集样本比较少,考虑使用交叉验证。
4、测试不同的$k$值以及距离度量$L1,L2$。
5、如果预测时间过长,考虑使用近似NN库(Approximate NN library)。
6、记录超参数。不应该使用验证集来训练(最后的模型再用验证集训练),因为这样可能会导致超参数发生变化。正确的做法是使用测试集来评估超参数的效果。