可视化神经网络,观察各层学到了什么
可视化卷积网络学到的内容
可视化卷积网络学到的内容已经有所研究,这里介绍相关工作。
可视化激活值和第一层权重
激活层
最直接的方法是前向传播过程中,可视化激活值。对于使用ReLU的网络,激活图看起来相对点状且密集(relatively blobby and dense),随着训练进行,激活图变得稀疏,激活值出现在某一区域。一个可能出现且容易注意到的问题是,可视化激活图为零(对于许多输入来说),这是dead filter,这可能是学习率过高导致。

上图是AlexNet输入一张猫的图片后的激活图。左边是第一层CONV的得激活图,右边是第五层CONV值的激活图。每张激活图对应一个滤波器。可以看出激活图是稀疏的(大部分值为零)且在某些固定位置激活。
卷积/全连接滤波器
权重可视化。最常见的是可视化第一层的权重,因为它直接对应输入原始数据,后面层的权重也可以可视化。可视化权重比较有用,因为训练良好的网络,权重可视化后比较平滑,没有什么噪声。如果可视化后噪声很多,说明网络可能没有训练好,或者正则化强度不够导致了过拟合。

左边是AlexNet权重可视化。左图对应第一个CONV权重,右图对应第二个CONV权重。左图权重平滑,说明网络训练良好。有彩色和灰度图是因为AlexNet包含两个数据流,一个是高频率的灰度图,一个是低频率的彩色图。第二层CONV的权重也是平滑,没有噪声。
寻找使网络“最激活”的图像
还有一种可视化技术,把很多图像喂给网络,跟踪一些神经元的激活值,查看那些图像能使得神经元激活值最大;通过这个图像就可以知道神经元在寻找什么样的图片。论文Rich feature hierarchies for accurate object detection and semantic segmentation就属于这一种。

上图是AlexNet第5层池化层中神经元值对应的图。白色区域是神经元的感受视野。神经元对上半身、文字和高光亮相应较大。
ReLU神经元本身没有意义。可以把多个神经元当做空间的一个向量,代表图片中的一个patch。可以参考 Intriguing properties of neural networks
使用t-SNE嵌入
卷积网络可以看做逐渐把图片转换为线性分类器可分特征的过程。我们可以把图片嵌入到2维空间中,这样,低纬度表示时它们距离比高纬度表示更小。t-SNE就是最出名的一种嵌入方法。
为了完成嵌入,使用CNN提取特征(AlexNet中是在分类器前面的4096维的向量),把这些向量嵌入到t-SNE得到每个图片的2维向量。对应图片可以网格形式展示。

临近的图像,高维空间表示也临近。注意到临近的图像是基于类别或语义的临近,而不是基于像素或颜色。更多参考t-SNE visualization of CNN codes
遮挡部分图像
当卷积网络分类图像时,怎么才能确定是识别了图像内容,而不是图像背景呢?一个研究方法是通过遮挡部分图像来确定网络对图像哪部分感兴趣。通过遮挡不同部分,对应正确类别概率可以可视化为2维热力图。论文Visualizing and Understanding Convolutional Networks中讲述了方法。
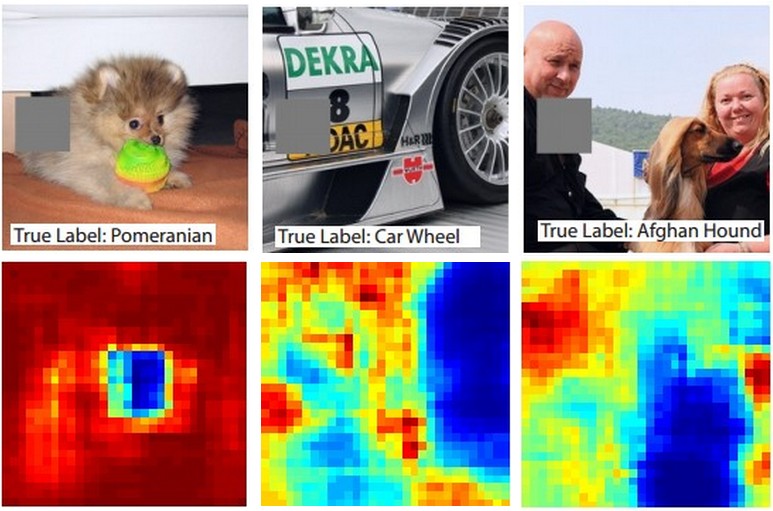
上面三幅图像为输入图像,灰度部分为遮挡。下图是通过遮挡不同部分,得到对应正确类别概率生成的热力图。可以看出,遮挡关键部分,会使正确类别概率下降。
可视化数据梯度等
数据梯度Data Gradient
Deep Inside Convolutional Networks: Visualising Image Classification Models and Saliency Maps
反卷积网络DeconvNet
Visualizing and Understanding Convolutional Networks
反向传播指导Guided Backpropagation
Striving for Simplicity: The All Convolutional Net
基于CNN重建原始图像
Understanding Deep Image Representations by Inverting Them
保留多少空间信息
Do ConvNets Learn Correspondence? (tldr: yes)
Plotting performance as a function of image attributes
ImageNet Large Scale Visual Recognition Challenge
Fooling ConvNets
Explaining and Harnessing Adversarial Examples