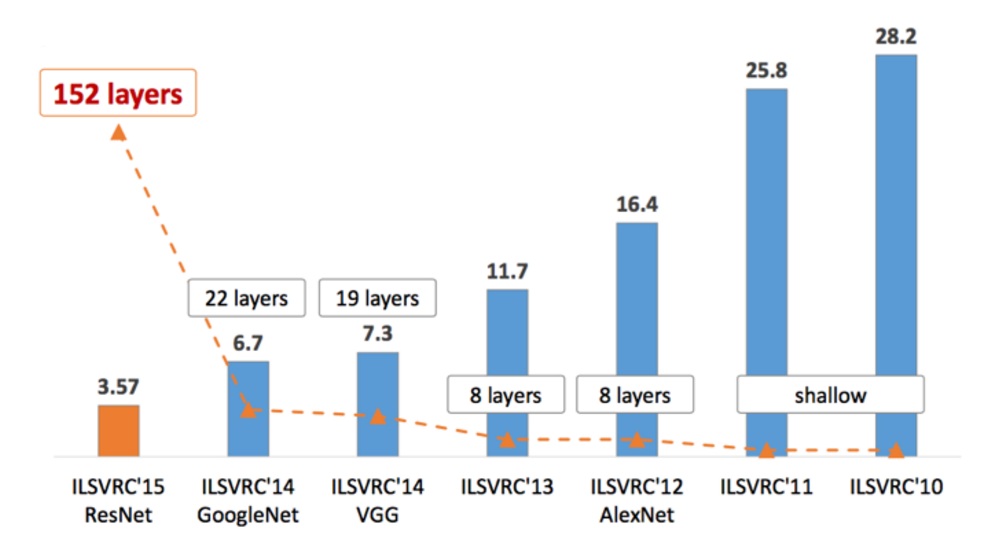
ImageNet Large Scale Visual Recognition Challenge是图像分类领域的比赛,记录一下历届冠军/经典论文的笔记。
LeNet
LeNet并没有参与ILSVRC比赛,但是它是卷积网络的开上鼻祖。LeNet主页上可以看到其详细信息,它是用来识别手写邮政编码的,论文可以参考Haffner. Gradient-based learning applied to document recognition
LeNet又称LeNet-5,它是一个7层的网络,
它的深度为5,包含2个卷积层和2个全连接层和1个Guassian connection。如下图: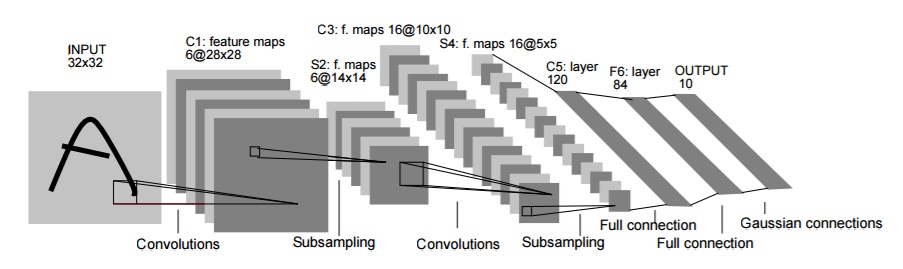
它的输入数据height和width是[32x32],MINIST数据集。
- 第1层卷积核大小[5x5],步长为1,输出为[28x28x6]。
- 第2层是池化层,进行下采样。池化核[2x2],步长为2,因此输出为[14x14x6]。论文中提到的池化方法,类似卷积,用[2x2]权重和感受视野做内积运算,得到结果;既不是MAX池化,也是不AVERAGE池化。
- 第3层是卷积层,共有16个卷积核,卷积核size[5x5]。通常卷积核depth和输入的depth相同,这里并不是。论文中定义了一个Connection Table,通过这个Table,可以看出每个卷积核和前一层那些feature map相连接。具体可以参考论文。之所以卷积核depth和输入depth不同,是因为1、non-complete连接可以减少参数个数;2、更重要的是打破了对称结构。这样得到的输入后,不同的feature map提取了不同的特征,因为它们输入不同。得到的输出为[10x10x16]
- 第4层是下采样层,和第二层的下采样类似。得到的输出为[5x5x16]。
- 第5层是卷积层,卷积核[5x5],个数为[120],depth为[16];这样得到的输出为[1x1x120]。这样看来本质是一个全连接层,用卷积层是因为输入可能变大,这样得到的输出就不再是[1x1]了。
- 第6层是全连接层,输出为大小为84。这一层输出经过了非线性函数sigmoid。
- 第7层是输出层,它有欧式径向基函数(Euclidean Radial Basis Function)RBF组成,没类一个单元,包含84个输出。单元$y_i$: $$ y_i = \sum_j(x_j - w_{ij})^2 $$ 也就是,每个RBF单元计算输出向量和参数向量之间的欧式距离。和参数向量越远,输出越大;RBF的输出可以理解为衡量输入模式和RBF类别相关联模型之间的惩罚(匹配程度)。从概率角度看,RBF输出可以看做是和第6层输出的高斯分布的非负log-likelihood。给定一个输入,loss函数使得第6层输出和RBF参数向量足够接近。
LeNet是最早的卷积神经网络结构,它的开创了神经网络基本结构CONV->POOL->非线性算子;在此之后,卷积神经网络沉寂多年。
AlexNet
AlexNet(http://www.cs.toronto.edu/~fritz/absps/imagenet.pdf)是2012年ILSVRC的冠军,且准确率远超第二名(top5 error rate15.3%,第二名为26.2%)。AlexNet介绍论文为ImageNet Classification with Deep Convolutional Neural Networks。
AlexNet结构如下: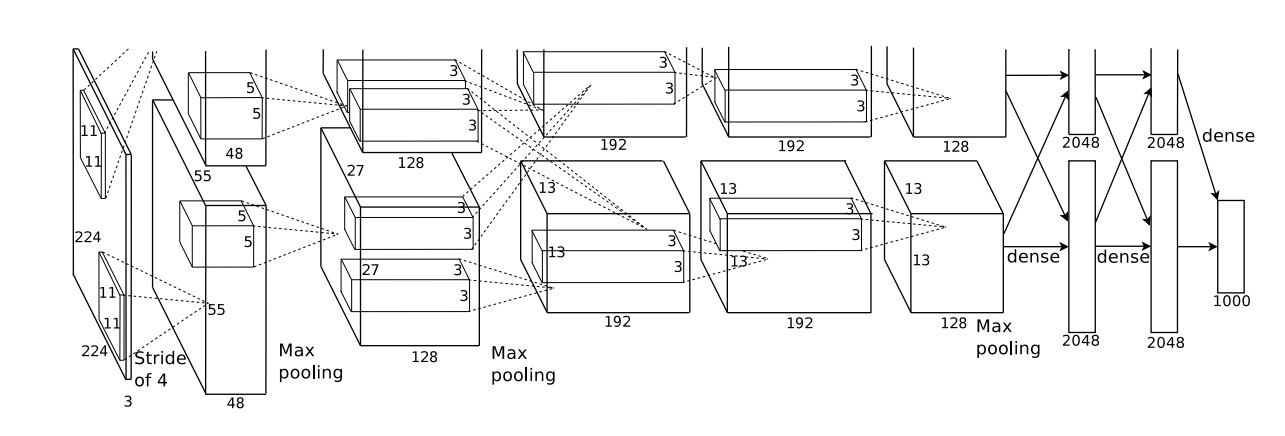
上图采用了模型并行,网络分在了2个GPU中。AlexNet共有8个包含参数的层,其中5个卷积层,3个全连接层,最后一个全连接层后面是softmax层。具体网络结果不再赘述,总结一下AlexNet创新点:
使用了ReLU非线性激活替代
tanh和sigmod,加快了训练速度。因为训练网络使用梯度下降法,非饱和的非线性函数训练速度快于饱和的非线性函数。下图是训练4层网络准确率和迭代次数关系,使用数据为CIFAR-10: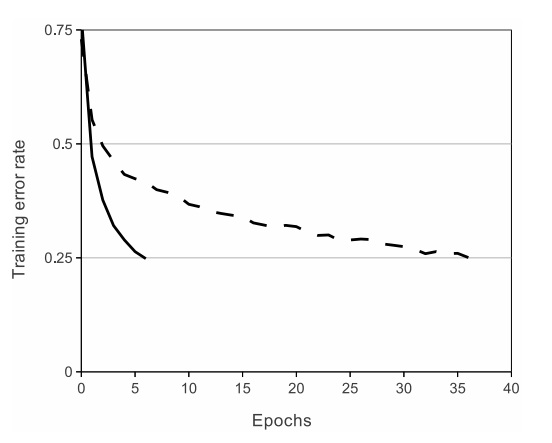
使用了LRN(Local Response Normalization)。LRB已经被证实基本没有效果,不再介绍。
使用重叠的Pooling
CNNs中的POOL层一般不会重叠,即步长大于等于池化核。但是AlexNet中,池化核的感受视野之间有重叠,例如池化核[3x3],步长却为2。使用了数据增强。为了减小过拟合。数据增强包括:1、随机crop图像。2、改变图像RGB通道强度。
使用了Dropout。也是为了减少过拟合。使用了Dropout后,每次前向/后向传播,网络结构都不相同;训练完成后,再把这些网络组合起来。使用了Dropout后,会增加训练时迭代的次数。
AlexNet的意义在于,使得CNNs重新回到人们视野,再次掀起来对CNNs研究的热潮。
ZFNet
ZFNet是2013你那ILSVRC的冠军。ZFNet论文为Visualizing and Understanding Convolutional Networks。ZFNet的网络结构,是在AlexNet上进行了微调: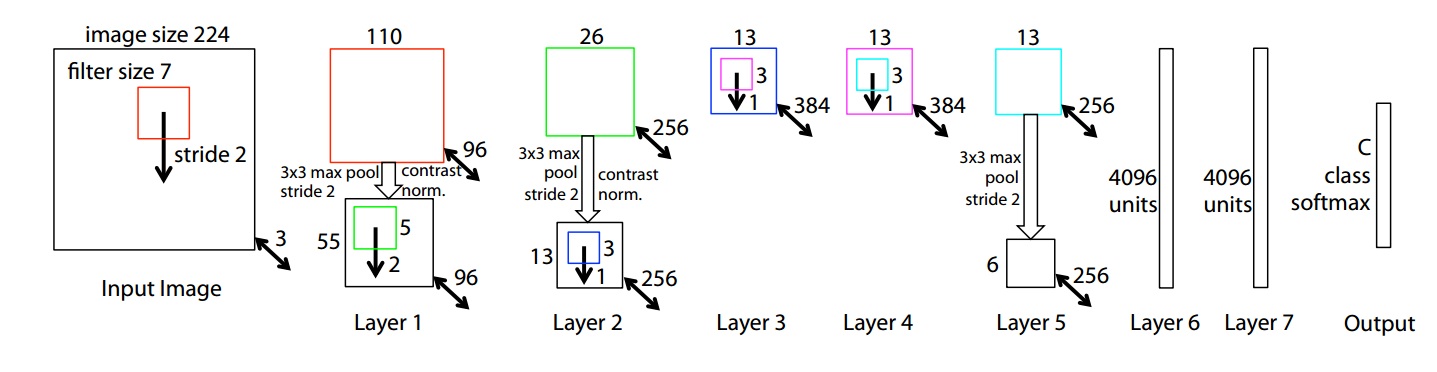
ZFNet的意义不在于它获得了2013年ILSVRC的冠军,而是解释了为什么CNNs有效、怎么提高CNN性能。其主要贡献在于:
使用了反卷积,可视化feature map。通过feature map可以看出,前面的层学习的是物理轮廓、边缘、颜色、纹理,后面的层学习的是和类别相关的抽象特征。
与AlexNet相比,前面的层使用了更小的卷积核和更小的步长,保留了更多特征。
通过遮挡,找出了决定图像类别的关键部位。
通过实验,说明了深度增加时,网络可以学习到更好的特征。
GoogLeNet
GoogLeNet是2014年ILSVRC冠军。具体可以参考Going Deeper with Convolutions。GoogLeNet为22层,比以往网络都深,结构参数如下: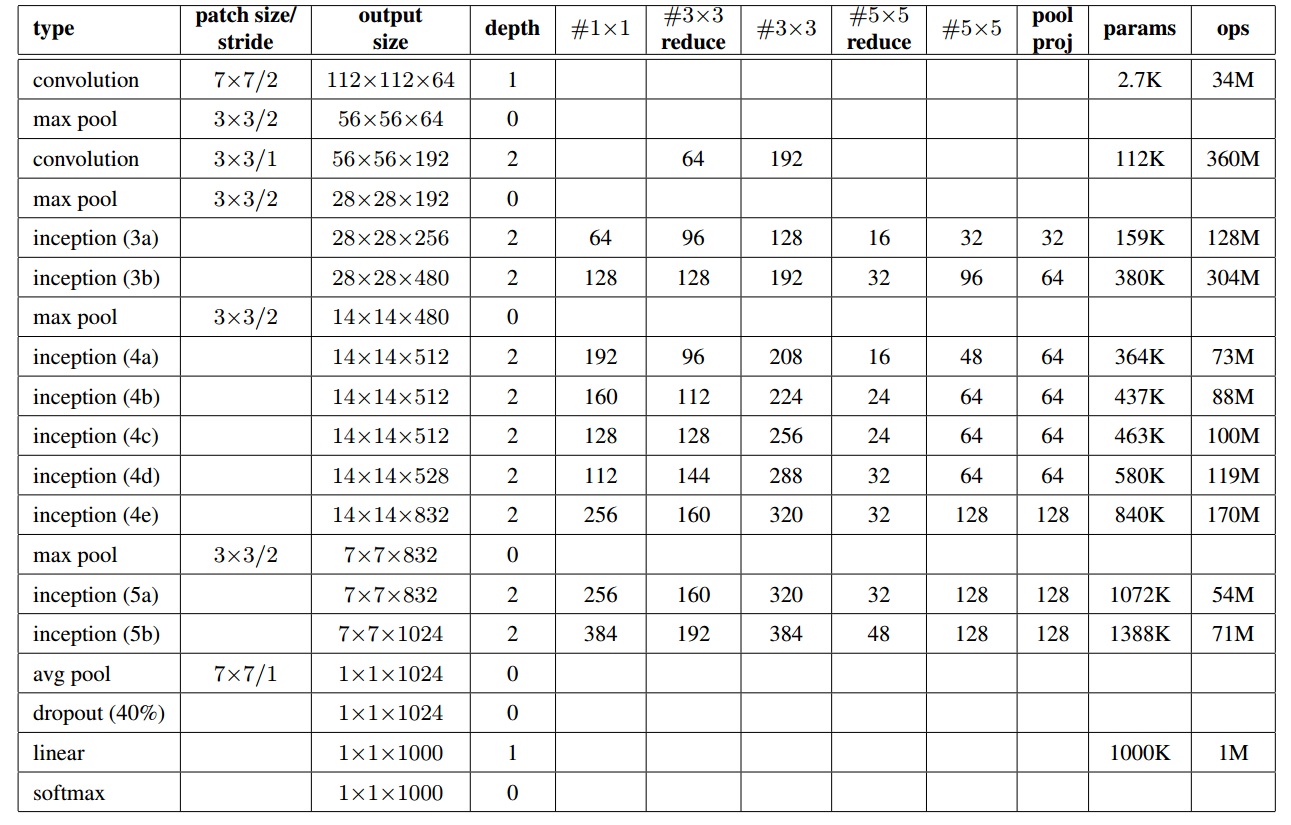
GoogLeNet创新了新的网络结构形式,其特点如下:
使用了1x1卷积;使用1x1卷积,1、增加了深度,2、降维,减小计算量。
使用了Inception结构。其结构如下:
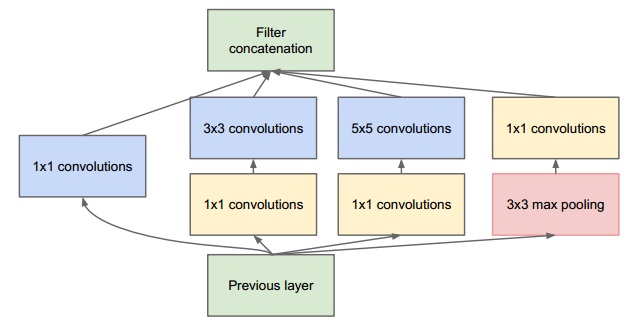
1x1卷积目的已知。卷积核3x3、5x5是为了方便(pad=1和pad=2保持空间大小不变),额外增加一个池化会有额外益处。低层特征,经过Inception结构提取,又把特征混合到一起,空间大小不变。连续重复这样的结构,组成了GoogLeNet。使用average pooling代替了full-connect。最后一层为softmax用来分类。
前面几层依然是CONV-POOL-CONV-CONV-POOL,后面才是Inception结构。
VGGNet
VGGNet是Oxford大学Visual Geometry Group提出的,目的是研究深度对卷积网络的影响。VGGNet使用简单的3x3卷积,不断重复卷积层(中间有池化),最后经过全连接、池化、softmax,得到输出类别概率。VGGNET共有6种不同类型配置,命名为A-E,深度从11(8个卷积核3个全连接)到19(16个卷积核3个全连接);每个卷积层的depth,从一开始的64到最后的512(每经过一个max-pooling,就增加一倍),具体网络配置如图: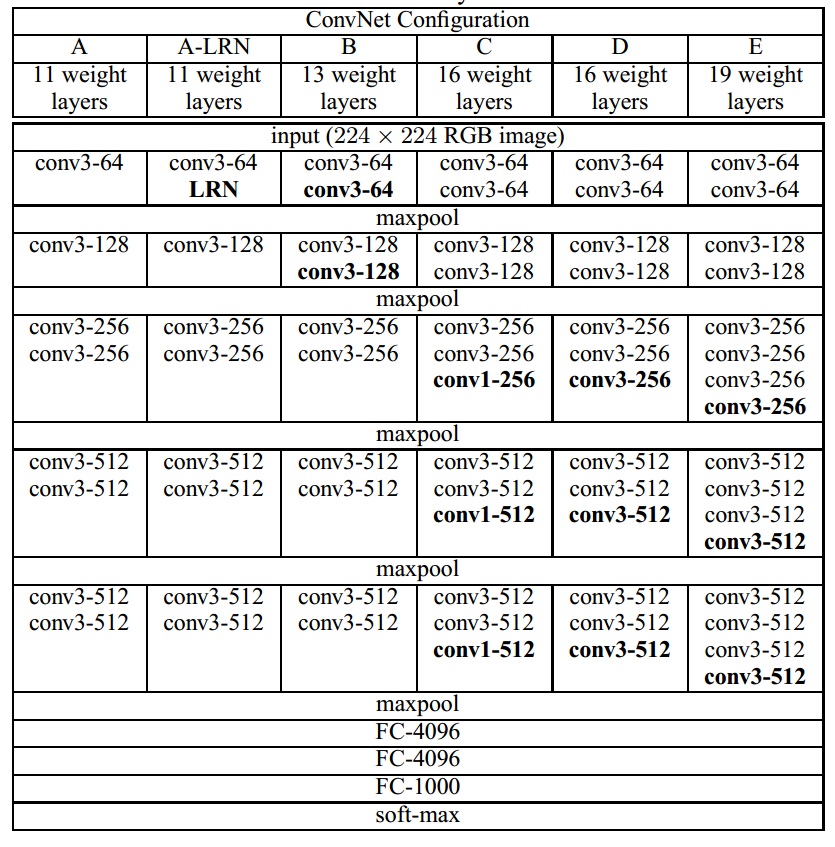
VGGNET采用AlexNet思想,网络架构为CONV-POOL-FC这种形式,其卷积层所有卷积核都是3x3,这样pad=1时,卷积层输入输入空间size不变。VGGNET特点包括:
所有卷积层都是3x3。连续多个卷积层,后面卷积层神对于输入的感受视野会变大,如连续2个3x3卷积层,第二层每个神经元感受视野为5x5;连续3个3x3卷积层,第三层每个神经元感受视野为7x7。这样做,1、多个非线性表达能力强于1个非线性。第二卷少了参数数量。depth为$C$时,连续3个卷积核参数数量$3(3\times 3 C^2)=27C^2$,单个7x7卷积层参数个数$7 \times 7 = 49C^2$。
1x1卷积核,在不影响卷积层感受视野情况下,增加非线性,增强表达能力。
ResNet
ResNet是2015年ILSVRC的冠军,其论文为Deep Residual Learning for Image Recognition。ResNet也是创新了网络的结构形式,引入了残差网络(residual net)。ResNet的残差结构如下: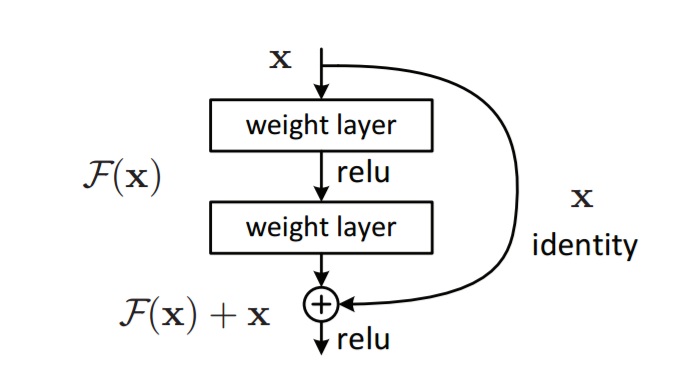
未加残差结构时,学习映射为$H(x)$,但是$H(x)$不容易学;加上参加结构后,学习映射变为$F(x)=H(x)-x$,学习$F(x)$比学习$H(x)$容易,那么通过学习$F(x)$来得到$H(x)=F(x)+x$,这就是residual结构。
ResNet主要创新:
- 发现degradation problem,更深的网络准确率未必更好。
- 引入残差结构,是深层网络优化变容易,使网络更深。
总结
同构上面各个网络,可以看出,网络变得越来越深,准确率变得越来越低。